La pregunta que lo empezó todo
Después de lanzar kotlin-container, @RoFerreiraDev me hizo una pregunta que me llevó a investigar más de lo que esperaba:
Buenísimo, resolución automática sin configuración suena a menos boilerplate. Cómo maneja los scopes?
La respuesta honesta en ese momento: no los manejaba. El contenedor tenía dos tiempos de vida — factory (nueva instancia cada vez) y singleton (una instancia para siempre). Sin scopes, sin límites de ciclo de vida, sin hooks de limpieza.
Y viniendo de PHP y Node.js, nunca los había necesitado.
Por qué nunca necesité scopes antes
En PHP, cada request es un proceso nuevo. Los singletons mueren cuando el request termina. El runtime es el scope — se obtiene aislamiento por request gratis.
En Node.js, típicamente se pasa el contexto de forma explícita o se usa AsyncLocalStorage. No hay un problema de singletons de larga vida porque se controla el ciclo de vida a través de closures y argumentos de función.
Kotlin en la JVM es diferente. Servidores como Ktor y Spring corren en procesos de larga vida con threads persistentes. Un singleton vive para siempre. Un factory crea una nueva instancia en cada llamada. Ninguno da lo que muchas veces se necesita: una instancia compartida dentro de un contexto acotado — como un request HTTP, un job en background, o una sesión de WebSocket.
Ese es el hueco que llenan los scopes.
El problema concreto
Imagina un DbTransaction en un servidor Ktor:
- singleton — una transacción compartida entre todos los requests. Desastre.
- factory — cada
resolve()crea una nueva transacción. Dos servicios en el mismo request tienen transacciones distintas. No pueden compartir un commit. - scoped — una transacción por request. Todos los servicios dentro de ese request la comparten. Se destruye cuando el request termina.
El patrón siempre es el mismo: se necesita un singleton dentro de un límite, no un singleton global.
Cómo lo hacen Koin y Dagger
Antes de diseñar nada, estudié cómo los dos principales frameworks de DI en Kotlin manejan scopes.
Koin usa un DSL con scopes nombrados y gestión explícita del ciclo de vida:
KOTLINval module = module {
scope(named("session")) {
scoped { SessionData() }
scoped { CartService(get()) } onClose { it?.clear() }
}
}
val scope = getKoin().createScope("session_123", named("session"))
scope.close()
Dagger usa anotaciones en tiempo de compilación. Los scopes son marcadores ligados a instancias de componentes:
KOTLIN@Scope
annotation class RequestScope
@RequestScope
class DbTransaction @Inject constructor()
No hay un close() en runtime — cuando se pierde la referencia al componente, todo es recolectado por el GC.
El modelo de Koin era más cercano a lo que quería (runtime, basado en reflexión), pero los scopes nombrados y los calificadores se sentían como ceremonia innecesaria para mi caso de uso.
Las decisiones de diseño
Pasé por varias rondas de preguntas antes de escribir código. Esto es a lo que llegué:
Los scopes son contenedores hijo
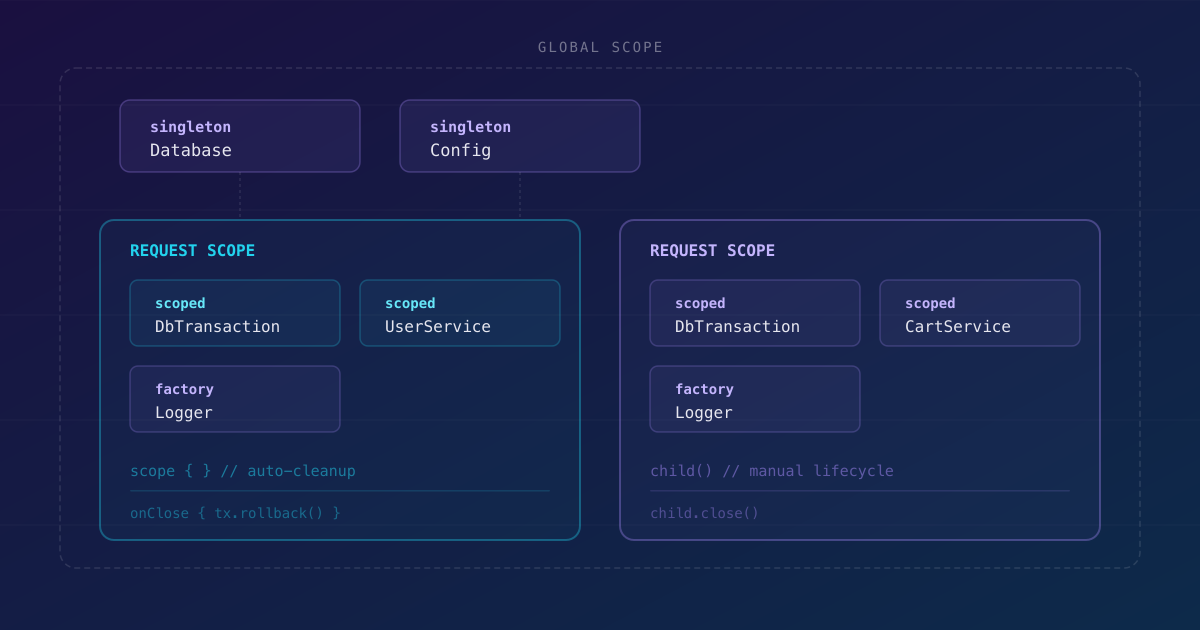
Un scope puede hacer todo lo que un contenedor puede — registrar bindings, resolver dependencias, invocar funciones. La única diferencia es que tiene un padre y un ciclo de vida.
Este fue el insight más importante. Significó que no necesitaba una implementación separada de Scope; un scope es simplemente un contenedor con una referencia a un parent.
Tres tiempos de vida
| Tiempo de vida | Comportamiento |
|---|---|
factory |
Nueva instancia en cada resolve() |
singleton |
Una instancia para siempre (global) |
scoped |
Una instancia por scope |
Creación por bloque y explícita
Se puede usar scope { } para limpieza automática o child() para gestión manual del ciclo de vida.
Hooks de disposición + AutoCloseable
Se puede adjuntar onClose { } a cualquier binding scoped. Si no se hace, y la instancia implementa AutoCloseable, se cierra automáticamente.
Scopes anidados
Cada scope obtiene sus propias instancias scoped. Cerrar un padre se propaga en cascada a los hijos, del más profundo al más superficial.
Sin scopes nombrados
Esta fue la decisión más opinada. Koin y Dagger tienen scopes nombrados/tipados. Yo elegí no tenerlos. El propósito del scope se define por lo que se registra en él, no por un nombre.
La sintaxis
Registro:
KOTLINval container = Container()
container.scoped<DbConnection> { DbConnection(resolve<Config>()) }
.onClose { it.disconnect() }
Uso por bloque (auto-close):
KOTLINcontainer.scope { scope ->
val db = scope.resolve<DbConnection>()
// usar db...
} // el scope se cierra aquí, db.disconnect() se ejecuta
Ciclo de vida explícito:
KOTLINval scope = container.child()
scope.resolve<DbConnection>()
scope.close()
Scopes anidados:
KOTLINcontainer.scope { outer ->
outer.scope { inner ->
// inner obtiene sus propias instancias
// inner se cierra primero, después outer
}
}
Por qué no hay scopes nombrados
Los scopes nombrados resuelven un problema de framework: cuando el framework crea scopes automáticamente y necesita enrutar bindings al tipo de scope correcto. En Android, Hilt liga bindings @ActivityScoped al ciclo de vida del Activity, y @FragmentScoped al del Fragment. El framework necesita saber a qué scope pertenece un binding.
En nuestro diseño, el usuario crea los scopes y registra en ellos directamente. Los service providers definen el propósito del scope:
KOTLINclass RequestScopeProvider(private val request: HttpRequest) : ServiceProvider {
override fun register(container: Container) {
container.singleton<RequestId> { RequestId(request.id) }
container.singleton<CurrentUser> { CurrentUser(request.userId) }
container.scoped<DbTransaction> { DbTransaction(resolve<DataSource>()) }
.onClose { it.rollbackIfOpen() }
}
}
fun handleRequest(container: Container, request: HttpRequest) {
container.scope { scope ->
scope.register(RequestScopeProvider(request))
scope.resolve<RequestHandler>().handle()
}
}
El "nombre" es el provider. El "targeting" es a qué scope se le pasa. No se necesita un sistema de calificadores.
Una implementación, no dos
La primera versión tenía dos clases: Dependencies para el contenedor raíz y ScopeImpl para los scopes. Duplicaban casi todo — mapa de bindings, mapa de singletons, métodos de registro, lógica de resolución.
Después me di cuenta: si un scope es un contenedor hijo, y un contenedor es un scope sin padre... son lo mismo. La versión refactorizada es una sola clase Dependencies con un parámetro parent opcional:
- Root (
parent = null): se retorna comoContainer,close()es un no-op - Child (
parent = algo): se retorna comoScope, con gestión completa del ciclo de vida
Una clase, un camino de resolución, cero duplicación.
Lo que aprendí
Construir esta feature cambió cómo pienso sobre la gestión de tiempos de vida en DI. Los puntos clave:
-
Los scopes existen porque los procesos sobreviven a los requests. Si el runtime muere después de cada request (como PHP), no se necesitan. Si no (como servidores JVM), sí.
-
Los scopes nombrados son una preocupación de framework, no de contenedor. Si se controla la creación de scopes, no se necesitan nombres. Si un framework crea scopes automáticamente, los nombres se vuelven necesarios.
-
Scopes y contenedores hijo son la misma abstracción. Un scope es un contenedor con un padre y un ciclo de vida. Una vez que se ve así, la implementación se simplifica dramáticamente.
-
Las mejores features nacen de preguntas. Toda esta feature empezó con un tweet. Gracias @RoFerreiraDev por hacer la pregunta correcta.
La feature de scoping está disponible en kotlin-container. Revisa el README para la documentación completa de la API.